This post will walk through an implementation of the transactional outbox pattern using Azure Functions and Cosmos DB.
The source code can be found at https://aka.ms/event-driven-architecture.
A little bit about microservices
In many distributed applications, it is typical for services to independently maintain their own datastore. This approach is used frequently in microservices and helps address challenges such as scalability, deployment, and agility by giving each service some level of autonomy.
Another characteristic that is often seen in this architectural pattern is the use of messaging to enable asynchronous communication between services. Messaging solutions like Azure Service Bus, Kafka, Event Hubs, and ActiveMQ are just a few of the available options that support this type of data exchange.
When these two patterns are embraced and used effectively, many of the promises of microservices can often be achieved. However, very rarely do these types of decisions come without tradeoffs.
Let’s use the popular example of an ordering system to dissect a key challenge: distributed transactions. The diagram below presents a frequently seen implementation in microservices:
In this design, the API, or microservice, represents an order management system. The flow of operations is as follows:
- Incoming requests from a client application are made to the API.
- The API performs some validation and business logic, then saves the data to its dedicated database.
- After the data is persisted, the service then makes a call to a message broker to publish a message or event for other services to consume.
This seems really simple, so what’s the problem?
For starters, issues can arise here when the message broker is unavailable. Also, what if there is a runtime error or exception during or even before the publishing step; how does that get resolved?
This leaves the ordering service, and quite possibly the data, in an inconsistent and brittle state. Even worse, it now puts the responsibility on the service to somehow rectify the situation. Ideally, this microservice should only be in charge of managing orders and should not be involved in how or if the other services receive those messages.
Distributed transactions in microservices
In monolith and many older applications, we commonly used transactions that spanned over multiple systems. Since everything was considered to be local and within our control, applying ACID principles was possible.
As we move towards microservices, this becomes increasingly challenging. Approaches such as implementing a multi-phase commit protocol are difficult and often require heavy weight infrastructure to pull off.
Assume you don’t have distributed transactions!
In most cases, the best thing to do it is to move away from this approach and embrace patterns that are tailored towards distributed systems and applications. This means that we should assume distributed transactions are no longer an option. We avoid 2-phase commits, dual writes and other related patterns that may have worked previously when the infrastructure of the solution was more centralized.
The transactional outbox pattern
In the order system example, the message broker and database are two different resources. Our goal is to ensure that messages are going to be eventually published to the message broker, and ultimately available for the other services, while still persisting the order to the database.
To make this possible, we will need to save the order information and the message that we wish to publish to the database in a single transaction.
This sequence diagram shows the first part of the outbox pattern by making use of a transaction to save both the order details and message in an atomic operation:
The second half of this pattern requires another process or worker that will be responsible for retrieving the pending messages from the database. Once successfully retrieved, it can then proceed to publish the corresponding messages and update the state of the entries accordingly:

The outbox processor will perform the following actions:
- Get the outbox entries (the pending messages).
- Publish the messages to the message broker.
- Update the outbox entries to reflect their published state.
The complete sequence diagram for the transactional outbox pattern now looks like this:

The outbox pattern allows us to avoid the distributed transaction but still atomically save to the database and publish a message.
Implementing the outbox pattern with Azure Functions and Cosmos DB
The remainder of this post will focus on an implementation of the transactional outbox pattern in Azure. There are many ways to implement this pattern, and we’ll use Functions and Cosmos DB to demonstrate an intriguing, event-driven option.
The architecture for the solution is represented in the following diagram:

The overall flow can be broken down into these steps:
- Incoming orders are sent from a client application to an HTTP-triggered Azure Function.
- The Azure Function will save both the order details as well as any events that should be published to Cosmos DB using a single transaction.
- Another Azure Function, the outbox processor, is invoked from the Cosmos DB change feed when the transaction completes.
- Events waiting to be published are retrieved from Cosmos DB.
- If there are any pending events, the function will attempt to publish them to a message broker. Azure Service Bus is used in this example to showcase an important feature called duplicate detection, more on that later.
- Finally, once published, the function will update the corresponding entries in Cosmos to a “Processed” state.
Cosmos DB and choosing a partition key
Before diving into the code, we have to set up a bit of infrastructure. The API for NoSQL is native to Cosmos DB and it will be used here to store the order details and messages in a document format. After the database is created in Cosmos, we will need to create a container to store all the data. Choosing the partition key here is critical.
Transactions in Cosmos DB must share the same partition key and container.
For each incoming order request, we will insert two documents: one for the order details and another for the message that will be published. Each document will have a unique ID, of course, but also share a common property for the order ID. This property (orderId) is the perfect candidate for a partition key when creating the container:

Azure Functions – Receiving orders and using transactions
The first Azure Function is responsible for accepting incoming orders and inserting two documents into a Cosmos DB container within a single transaction.
To support transactions, we will have to use the Cosmos DB SDK instead of the output binding. It all starts with dependency injection in the Startup.cs file to pass in an instance of the Cosmos client:
The HTTP-triggered function takes the incoming request and prepares two documents for insertion into the container. A transactional batch is used to group both insert operations. This basically means that all the associated operations within the batch will either succeed or fail together. The entire function code is represented here (gist reference):
Why not use the output binding for Cosmos in this function?
The output binding for Cosmos is great but it doesn’t satisfy our requirement to create a transaction for both of the insert operations.
Azure Functions – Outbox processor
In the outbox pattern, there needs to be a mechanism that initiates the retrieval of messages waiting to be published. That mechanism can be a job or even better, something that is event-based. The change feed in Cosmos DB outputs changes from a container in the order that they occur. Azure Functions provides a trigger for the container’s change feed.
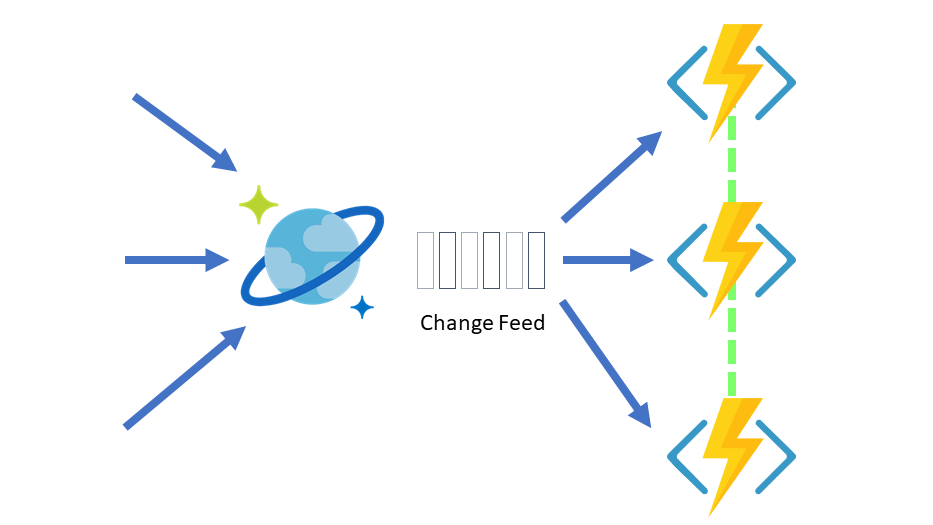
The function for the outbox processor will use the Cosmos DB change feed trigger, including a collection of other helpful bindings:
Let’s talk briefly about the trigger and bindings used in the function:
- CosmosDBTrigger – This trigger will be used to invoke the function. Rather than polling or scheduling a job to query the database for updates, the change feed from Cosmos DB will be the source of invocation.
- CosmosDB input binding with SQL query – The SQLQuery attribute will retrieve multiple documents that satisfy the query, in this case it will be for messages that are ready to publish.
- CosmosDB document client – This input binding provides a document client instance that will be used to update documents. After messages are published, the document client will update the state of the items to reflect the processed state.
- ServiceBus output binding – Publishes multiple messages to a Service Bus topic with the IAsyncCollector.
The code for the outbox processor function, in its entirety (gist reference):
With the outbox pattern implementation complete, it’s time to talk about one last piece: duplicate messages.
Duplicate detection with Azure Service Bus
It’s possible that publishing the same message more than once can occur. We all know that consumers should be idempotent so that processing the message multiple times will not change the state of the underlying system. In reality, this sounds trivial, but that is not the case in practice when there are multiple dependencies and systems involved.
Azure Service Bus has a great feature called duplicate detection that can help share some of this responsibility. When this feature is enabled for a queue or topic, it uses the MessageId property to identify duplicate messages when they are published. If a duplicate is found within the configured time window, it will be ignored and dropped – saving the downstream consumers from some extra work.
At the very end of the outbox processor function, the MessageId property it set to the OrderId to help reduce the possibility of duplicate messages.
Disclaimer: This doesn’t mean that the consumers are no longer responsible, or should not strive for idempotency. It is just another feature that can be used to help with the challenge of duplicate messages in an event-driven architecture.
Summary
It’s always fun taking an old pattern and implementing it in a modern way that is event-driven and takes advantage of services that integrate well together. I hope this implementation was useful and interesting. Please feel free to provide feedback if you see anything missing or incorrect, there is always room for improvement. 🙂
References
- Azure Functions
- Azure Cosmos DB
- Azure Cosmos DB change feed
- Azure Service Bus duplicate detection
- Source code
- Transactional outbox pattern

Thanks for sharing David, I have the following comments
1. I think the query “select * from Orders r where r.orderProcessed = false” is a cross-partition query that will consume more RUs negatively impacting the order creation process.
2. The consumers might be interested in knowing order updates as well, in which case the processor should subscribe to all the changes and not just ‘Orders created’
3. Customer Id is another candidate to consider for the partition key, it also solves the problem of ordering for orders coming from the same customer, which cannot be done with Order Id as the partition key.
What happens when the outbox processor fails to publish to outbox? Since the change feed is fetched on change trigger, this will leave some changes in the cosmos db, potentially until a next change happens, which also depends on how the change fetch is designed. Is there some retry mechanism on failure to publish? How is the pathological failure (repeated failure to publish) case handled?
You bring up a really interesting scenario. There is a bit of resiliency in the SDK for retries here. At the same time, the abstraction might be a bit much with the output binding since there aren’t any configuration details that we can make adjustments for (retry count, backoff, etc.). As much as I like the output bindings and the convenience they offer, perhaps this might be a better case for using the SDK directly again, with a try/catch block and some logging.
Here is updated example that uses the retry policy: https://github.com/dbarkol/transactional-outbox-pattern/blob/main/src/OutboxProcessor.cs
When a retry occurs due to an exception, the change feed event gets reprocessed. 🙂
Great article and very nicely mentioned how to implement the Outbox pattern.
I have few questions here –
Is the above outbox processor function is only built to handle for OrderCreated events? Because there would be minimum 2 more events like OrderPaid and OrderUpdated. So how would you handle that ? I believe we need separate outbox processor function for those events- do you think same as well ?
Also are you considering one container for all orders and outbox events ?
Thanks,
Arup
Thank you, Arup. Agree with you on both – another processor function could be used to handle other events. Need same container for orders and outbox events to satisfy transaction.